데이터 전처리는 머신러닝의 첫 번째 단계이며, 가장 중요한 작업이다.
머신러닝에서 가장 힘들고 하기 싫지만 너무나도 중요한 작업이 바로 데이터 전처리이다.
모델이 성능을 내기 위해서는 반드시 데이터가 정제된 상태에서 학습을 수행해야 하기 때문이다.
지금까지 알아본 내용은 모두 머신러닝 지도 학습 프로세스에 해당한다.
지도 학습의 큰 그림은 다음과 같다.
데이터 전처리 → 학습/테스트 데이터 분할 → 모델학습 및 검증평가 → 예측 및 평가
지난 두 번의 포스팅에서 데이터를 분할하고 모델링(알고리즘 학습)과 교차 검증을 진행하며,
테스트 데이터로 예측을 수행하고 모델의 성능을 측정하는 과정까지 모두 살펴보았다.
남은 데이터 전처리 단계에서는 주로 다음과 같은 작업을 수행한다.
이 중 어떤 작업을 해줄지는 데이터를 보고 판단한다.
- 데이터 클린징
- 결손값(null/NaN) 처리
- 데이터 인코딩
- 데이터 스케일링
- 이상치 제거
- Feature 선택/추출/가공
결손값 처리는 첫 번째 Pandas 실습에서 살펴보았다.
간혹 성능을 저하시키는 feature를 제외하고, 필요한 feature만 추출하는 작업을 해주기도 한다.
이론적으로는 각 feature가 독립적이라는 가정 하에 feature가 많을수록 모델의 성능이 좋지만,
실제로는 그렇지 않는 경우도 많다.
이번 포스팅에서 알아볼 내용은 '데이터 인코딩'과 '데이터 스케일링'이다.
전반적으로 데이터를 살펴볼 때도 수행하는 이상치 제거, 결측치 처리 등의 작업과 다르게,
인코딩과 스케일링은 특히 머신러닝 데이터에 주로 사용되는 전처리 기법이다.
Feature 선택/추출/가공의 경우 이후 차원 축소 포스팅에서 다룰 예정이다.
데이터 인코딩
머신러닝 알고리즘은 숫자형 데이터만을 입력받고, 문자형 데이터는 입력받지 않는다.
데이터를 확인하고 시각화하는 것이 목적이라면 인코딩 작업을 해줄 필요가 없지만,
머신러닝이 목적인 경우 문자형 범주 데이터를 숫자형으로 변환(인코딩)하는 작업이 필요하다.
크게 두 가지 인코딩 기법이 존재한다.
문자로 된 범주 값을 숫자 형태로 단순 변환시키는 레이블 인코딩(Label Encoding)과,
범주 값 개수 n만큼 원소를 갖는 배열을 n개 생성하는 원-핫 인코딩(One-Hot Encoding)이다.
1) 레이블 인코딩(Label Encoding)
아래와 같이 범주형 데이터의 범주 값을 0부터 시작하는 숫자 값으로 변환해주는 방식이다.
sklearn.preprocessing 모듈에 자동으로 문자를 숫자로 바꿔주는 LabelEncoder가 존재한다.

레이블 인코딩은 한 가지 단점으로 인해 회귀 모델에서는 잘 사용되지 않는다.
분류 모델은 문제가 없지만, 회귀 모델의 경우 해당 방식이 알고리즘의 성능을 저하시킬 수 있다.
미래 데이터의 숫자 값을 예측하는 회귀 모델은, 단순히 범주 값을 구분하기 위해 레이블 인코딩에
사용된 숫자를 가지고 숫자 간 크기를 비교하는 알고리즘을 만들어낼 수 있다.
아무 의미 없는 숫자가 그 자체로 의미를 가지게 될 수 있기 때문에 레이블 인코딩을 쓰지 않는다.
2) 원-핫 인코딩(One-Hot Encoding)
범주 값의 개수를 원소의 개수로 가지는 배열을 범주 값의 개수만큼 생성하는 방식이다.
각 범주 값에 해당하는 위치만 값을 1로 지정하고, 나머지는 모두 0으로 채운다.
이러한 형태의 컬럼을 범주 값의 개수만큼(각 범주 값을 나타내는 더미 변수) 추가한다.
sklearn.preprocessing 모듈의 OneHotEncoder를 인코딩에 사용한다.

* 레이블 인코딩과 원-핫 인코딩 모두 Pandas를 사용하여 손쉽게 작업할 수 있다.
- 레이블 인코딩 : map 함수 사용
- 원-핫 인코딩 : pd.get_dummies(DataFrame)
실제로 sklearn.preprocessing 모듈에 비해 Pandas가 더 많이 사용된다.
실습 파일에서 두 가지 방식의 전처리 코드를 모두 확인해볼 수 있다.
데이터 스케일링
스케일링(Scaling)은 데이터 값의 범위를 일정한 수준으로 변환하는 전처리 기법이다.
모든 feature의 데이터가 동일한 기준을 가지고 수집되지는 않는다.
가령 같은 항목이라도 한 기업에서는 5점 척도로, 또 다른 기업에서는 7점 척도를 사용할 수 있다.
이처럼 제각각인 feature 값들의 기준을 맞춰주는 것도 알고리즘의 성능에 영향을 미칠 수 있다.
표준화(Standardization)와 정규화(Normalization)의 두 가지 스케일링 방식이 존재한다.
1) 표준화(Standardization)
각각의 feature를 평균이 0, 분산이 1인 표준 정규분포(Normal Distribution)로 변환한다.
개별 데이터에서 feature 전체의 평균을 빼고 표준편차로 나누어주면 된다.
쉽게 생각하면 feature의 평균이 기존의 평균 값에서 0으로 수평이동한 것이다.
표준화에는 sklearn.preprocessing 모듈의 StandardScaler API를 사용한다.
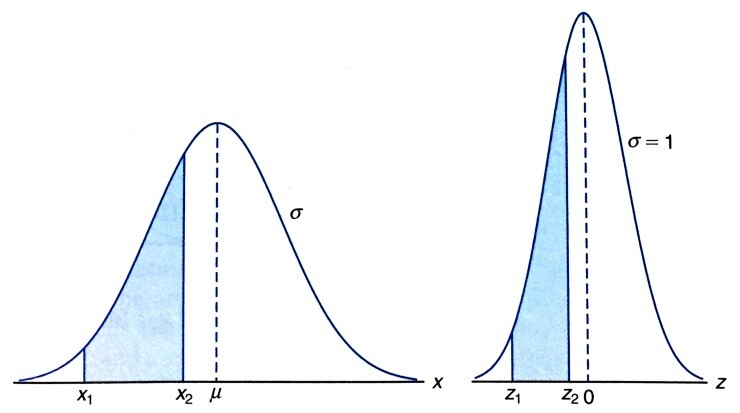
표준화된 feature의 개별 데이터는 Z값(Z-score)이라고 표현한다.
Z값이 -3보다 작거나 3보다 큰 데이터는 이상치로 처리한다. (이상치 확인 가능)
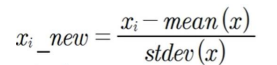
* 데이터를 정규분포 형태로 변환하는 두 가지 방법
- 표준화(Standardization)
- 로그 변환(Log Transformation)
수치형 변수의 크기와 분포가 중요한 선형 계열이나 거리 기반 알고리즘의 경우 데이터를
정규분포화하여 성능을 향상시킬 수 있는데, 대체로 표준화에 비해 로그 변환의 성능이 우수하다.
반면, 숫자의 크기가 성능에 영향을 주지 않는 트리 계열의 알고리즘은 정규분포화가 무의미하다.
선형 회귀(Linear Regression) 알고리즘 역시 거리 기반 알고리즘의 일종이다.
특히 연속적인 데이터를 다루는 선형 회귀 모델은 레이블(target)의 분포가 매우 중요하다.
따라서 레이블의 분포가 치우쳐 있다면 먼저 레이블을 로그 변환하는 경우가 많다.
레이블 데이터만 로그 변환하거나, 전체 데이터를 표준화한다.
표준화와 로그 변환 작업은 중복 수행하지 않는다.
2) 정규화(Normalization)
Feature들의 데이터의 범주가 다를 때 서로 다른 feature의 크기를 통일하기 위해 사용한다.
모든 feature의 데이터를 0부터 1까지의 값으로 변환한다. (음수 존재 시 -1부터 1까지의 값)
정규화에는 sklearn.preprocessing 모듈의 MinMaxScaler API를 사용한다.
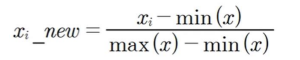
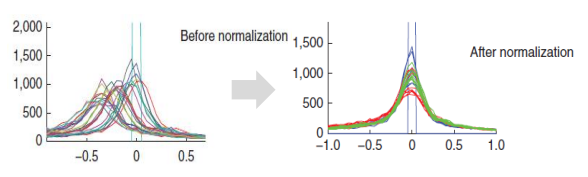
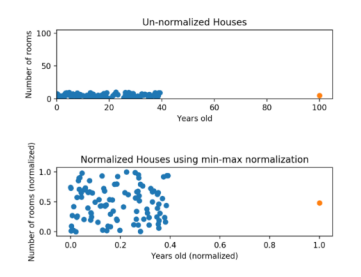
이상치가 존재할 경우 표준화/로그 변환이 정규화에 비해 나은 스케일링 방식이다.
아래 그림을 보면 정규화 후 분포가 개선되기는 했으나,
이상치가 분포의 최댓값인 1로 설정되어 나머지 데이터가 모두 0.4 이하의 값을 지니게 된다.
정규화를 수행하기 전에 이상치로 인해 나머지 값들의 범위가 좁아지는 것을 주의해야 한다.
아래 링크에서 데이터 인코딩과 데이터 스케일링 실습 코드를 확인할 수 있다.
1) 이상치 처리 및 상관 분석
https://github.com/tldnjs1231/data-analytics/blob/main/data-analytics-10-anomaly_detection.ipynb
GitHub - tldnjs1231/data-analytics
Contribute to tldnjs1231/data-analytics development by creating an account on GitHub.
github.com
2) 인코딩, 스케일링
GitHub - tldnjs1231/data-analytics
Contribute to tldnjs1231/data-analytics development by creating an account on GitHub.
github.com
3) KNeighborsClassifier
GitHub - tldnjs1231/data-analytics
Contribute to tldnjs1231/data-analytics development by creating an account on GitHub.
github.com
'2022 데이터 사이언스 > 빅데이터 분석과 모델링' 카테고리의 다른 글
| 12. 선형 회귀(2): 성능 평가 지표와 규제 선형 회귀 (0) | 2022.06.29 |
|---|---|
| 11. 선형 회귀(1): 단순/다중 선형 회귀 (0) | 2022.06.20 |
| 09. 교차 검증: cross_val_score, GridSearchCV (0) | 2022.06.20 |
| 08. 머신러닝 라이브러리: Scikit-learn (0) | 2022.06.20 |
| 07. 머신러닝의 이해 (0) | 2022.06.20 |