교차 검증을 통해 과적합된 데이터의 test 데이터 예측 정확도를 높일 수 있다.
데이터가 크면 상관없지만, small data의 경우 test 데이터에 대한 예측 성능이 떨어질 수 있다.
적은 양의 데이터를 학습시켰을 때 종종 모델이 학습 데이터에 '과적합'되기 때문이다.
(1) 과대적합(Overfitting)
- 학습 데이터를 과하게 적합되어 실제(test) 데이터에 대한 오차가 증가하는 현상
- 학습 데이터에 대하여 높은 정확도를 보이지만 새로운 데이터에 대한 예측 정확도는 저하
* 해결 방안
- 파라미터의 수가 적은 모델을 선택하거나 모델에 규제를 가하여 단순화
- 데이터 잡음(outlier, error) 제거
- 추가 데이터 확보(비용 등의 문제로 쉽지 않으므로 교차 검증을 통해 해결)
(2) 과소적합(Underfitting)
- 모델이 지나치게 단순하여 데이터의 패턴을 학습하지 못하고 학습 오류가 줄어들지 않는 현상
학습 데이터에만 지나치게 적합한 모델이 되어버리면 학습 데이터에 대한 예측 성능은 좋지만,
검증 데이터에 대한 예측 정확도는 오히려 낮게 나오는 경우가 있다.
이러한 과적합 문제를 해결하기 위해 교차 검증(Cross Validation)을 시행한다.

기존에는 데이터셋을 training 데이터와 testing 데이터로만 분할했다.
반면 교차 검증 시에는 기존 학습 데이터 중 일부를 validation 데이터로 확보한 후,
여러 세트로 구성된 학습과 검증 데이터셋을 가지고 학습과 평가를 반복하여 수행한다.
K Fold Cross Validation
가장 보편적으로 사용되는 교차 검증 방식은 K Fold 교차 검증이다.
- K Fold Cross Validation
- Stratified K Fold Cross Validation
전체 데이터셋에서 testing 데이터를 제외한 나머지 부분으로 K개의 데이터 Fold를 만들어,
이 중 1/K를 검증 데이터로, 나머지를 학습 데이터로 활용한 학습과 검증 평가를 반복 수행한다.
K개의 블록을 각각 한 번 씩 검증 데이터로 사용하므로 교차 검증 횟수는 K번이다.
아래의 경우 전체 training 데이터의 4/5만 학습을 시키고 주황색 부분은 검증 평가에 사용한다.
5번의 검증 평가 후 5개 데이터 Fold들의 평가 지표를 평균 낸 값이 최종 K Fold 평가 지표이다.
그러나, 데이터 Fold 생성 시 레이블 데이터의 불균형이 발생할 수 있다.
아래와 같이 특정 데이터가 학습 및 검증 레이블 중 한 쪽에만 과하게 치우쳐 분포하는 경우이다.
이 같은 불균형을 방지하고자 사용하는 것이 비율을 반영해 샘플링하는 Stratified K Fold이다.
불균형한 분포(레이블)를 가진 데이터이거나 small data인 경우에 유용하게 쓰인다.
교차 검증 실습: model_selection
실습에 사용할 두 가지 교차 검증 함수는 cross_val_score와 GridSearchCV이다.
두 개의 함수 모두 sklearn.model_selection 모듈에 속해 있다.
model_selection 모듈에는 교차 검증 함수와 더불어 train_test_split이 포함되어 있다.
1) cross_val_score
cross_val_score는 교차 검증을 쉽게 수행하도록 도와주는 API로,
폴드 세트 추출, 학습/예측, 평가 등 일반적인 K Fold 교차 검증 과정을 한 번에 수행할 수 있다.
2) GridSearchCV
GridSearchCV는 교차 검증과 하이퍼 파라미터(hyper parameter) 튜닝이 동시에 가능하다.
하이퍼 파라미터란 모델의 성능을 개선하기 위해 사용자가 모델링 시 직접 조정해주는 값이다.
사용자가 하이퍼 파라미터를 세팅해주면 이 값은 학습 과정을 제어하는 데 사용된다.
대조적으로, 회귀계수 등 다른 매개변수(파라미터) 값들은 훈련을 통해 모델 내부에서 결정된다.
GridSearchCV의 하이퍼 파라미터로는 max_depth와 min_samples_split이 있다.
주로 사용하는 DecisionTree 모델은 아래 그림처럼 계속되는 질문을 통해 학습하는 방식인데,
max_depth는 최대로 얼마나 깊이 질문 또는 학습해 들어갈지를 결정하는 하이퍼 파라미터이다.
그림에서 각 층의 depth는 위에서부터 0, 1, 2, 3이다.
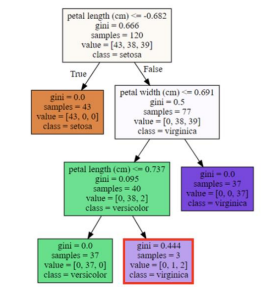
DecisionTree는 남은 샘플 개수에 따라 depth를 키울 것인지 멈출 것인지 결정하기도 한다.
min_samples_split은 다음 depth로 split 하도록 결정하게 되는 최소의 샘플 개수를 의미한다.
예를 들어 어떤 모델의 하이퍼 파라미터 값과 Fold 세트 수를 다음과 같이 설정했다고 하자.
max_depth : [1, 2, 3]
min_samples_split : [2, 3]
cv : 3
해당 모델은 max_depth 값이 1, 2, 3일 때와 min_samples_split 값이 2, 3일 때를 모두 시도,
최적의 하이퍼 파라미터 값을 찾아내 최고의 예측 점수를 도출한다.
따라서 이 모델의 총 학습/검증 횟수는 3 x 2 x 3 = 18이다.
머신러닝과 교차 검증
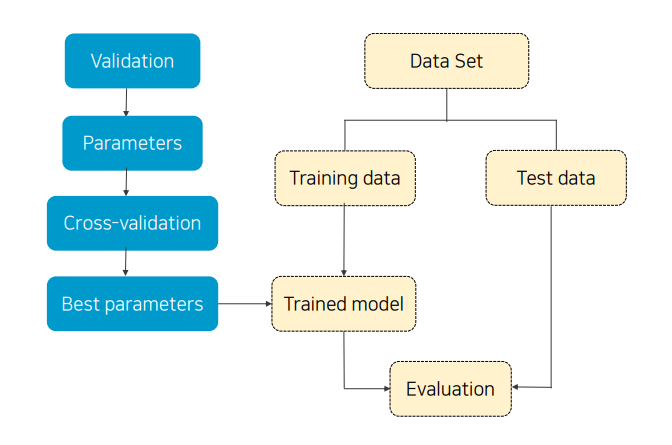
지난 포스팅에서 다룬 교차 검증 이전의 머신러닝은 그림의 노란색 부분에 해당한다.
파란색 부분은 교차 검증 과정을 보여준다.
기존 training data의 일부를 validation data로 편성하고,
하이퍼 파라미터 값을 지정해 교차 검증을 시행한 후 최적의 파라미터를 모델에 적용시킨다.
머신러닝과 교차 검증의 큰 그림을 이해했다면 교차 검증 실습을 해보자.
아래 링크에서 cross_val_score와 GridSearchCV 교차 검증 실습 코드를 확인할 수 있다.
https://github.com/tldnjs1231/data-analytics/blob/main/data-analytics-09-cross_validation.ipynb
GitHub - tldnjs1231/data-analytics
Contribute to tldnjs1231/data-analytics development by creating an account on GitHub.
github.com
'2022 데이터 사이언스 > 빅데이터 분석과 모델링' 카테고리의 다른 글
| 11. 선형 회귀(1): 단순/다중 선형 회귀 (0) | 2022.06.20 |
|---|---|
| 10. 데이터 전처리: 인코딩, 스케일링 (0) | 2022.06.20 |
| 08. 머신러닝 라이브러리: Scikit-learn (0) | 2022.06.20 |
| 07. 머신러닝의 이해 (0) | 2022.06.20 |
| 06. 데이터 시각화: matplotlib, seaborn (0) | 2022.06.20 |