Pandas를 사용하여 외부 데이터를 읽어와 정렬하고 분석할 수 있다.
지난 포스팅에서는 직접 만든 간단한 데이터로 실습을 진행했다.
현업에서는 외부 데이터를 분석에 사용하기 때문에,
웹 상의 데이터나 파일로 저장된 데이터 등 외부 데이터를 불러올 줄 알아야 한다.
Pandas를 사용해 CSV, JSON, HTML(표 데이터), MS EXCEL, SQL 등
다양한 형태의 데이터를 불러올 수 있는데, 앞으로 CSV 파일을 가장 많이 불러오게 될 것이다.
CSV 파일 불러오기
CSV 파일로부터 데이터를 불러와 데이터프레임을 생성하는 것은
데이터 분석을 위해 데이터프레임을 생성하는 가장 일반적인 방법이다.
CSV 데이터를 불러오는 .read_csv() 명령어는 구체적으로 아래와 같이 사용된다.
import pandas as pd
df = pd.read_csv('winequality-red.csv', sep=';')
- winequality-red.csv : csv 파일명
- sep=';' : 데이터구분자(;)
* CSV 파일은 기본적으로 데이터가 ' , ' 로 구분되어 있어 구분자를 지정해줄 일이 거의 없지만,
간혹 ' , ' 로 구분되어 있지 않은 데이터는 따로 구분자를 지정해준다.
인덱스 활용
(1) 특정 열을 행 인덱스로 설정
데이터프레임.set_index('열 이름')
(2) 행 인덱스 초기화
데이터프레임.reset_index()
.reset_index() 사용 시 행 인덱스는 0으로 시작하는 정수형 위치 인덱스로 초기화되고,
기존의 인덱스는 'index' 열에 포함되어 0번 열에 위치하게 된다.

drop=True 옵션 사용 시 기존 인덱스 삭제를 동시에 진행할 수 있다.
데이터프레임 정렬
1) 행 인덱스 기준 정렬
- df.sort_index() : 행 인덱스 기준 오름차순 정렬
- df.sort_index(ascending=False) : 행 인덱스 기준 내림차순 정렬
- df.sort_index(axis=1, ascending=False) : 컬럼 인덱스 기준 내림차순 정렬
* 행 뿐만 아니라 열에도 보이지 않는 인덱스가 0부터 존재
ascending=False : 내림차순 정렬 옵션
axis=1 : 열 방향 전환 옵션 (default : 행 방향)
axis = 0 axis = 1
↓ →
2) 특정 열 데이터 기준 정렬
데이터프레임.sort_values(by='...')
위 데이터프레임에서 df.sort_values(by='C1', ascending=False) 적용 시
:
Aggregation 함수
mean(), min(), max(), sum(), std() 등의 수치 계산 함수가 Aggregation 함수에 포함된다.
축 정보를 기준으로 데이터의 평균, 최대, 최소, 합, 분산 등을 구할 수 있다.
(1) df.mean()
행 방향으로 각 열의 평균을 구한다.
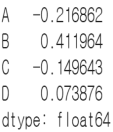
(2) df.mean(axis=1) / df.mean(1)
열 방향으로 각 행의 평균을 구한다.
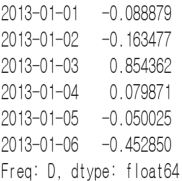
groupby 데이터 그룹화
groupby를 사용하여 같은 값을 하나로 묶어 통계 및 집계 결과를 얻을 수 있다.
데이터프레임.groupby('열 이름') 의 형태로 사용된다.
데이터를 그룹화한 후 Aggregation 함수와 결합해 통계 결과를 조회한다.
df.groupby('A').sum()

df.groupby(['A', 'B']).sum()

df.groupby('A').mean()[['C']] : 'A' 기준 grouping 후 평균 낸 데이터에서 'C' 열만 추출
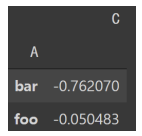
df.groupby('A').max()
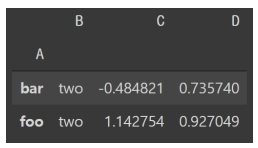
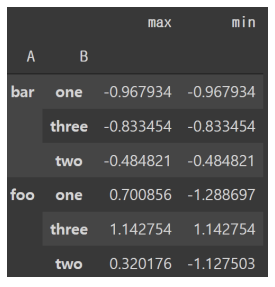
* .agg() 사용하여 여러 개의 Aggregation 함수 적용
df.groupby(['A', 'B'])['C'].agg([max, min]) : 'A', 'B' 기준 grouping, 'C'의 max, min
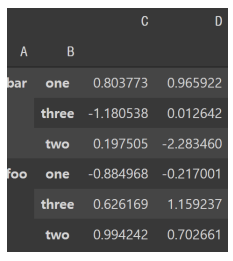
* 딕셔너리를 사용하여 여러 컬럼에 대해 다양한 Aggregation 함수 적용
df.groupby(['A', 'B']).agg({'C' : 'min', 'D' : 'mean'}) : 'C'의 min, 'D'의 mean
함수 매핑
매핑은 함수에서 input(x)을 output(y)에 대응시키는 것을 말한다.
여기서는 특정 함수가 데이터의 개별 원소에 접근하는 과정을 의미한다.
데이터프레임의 여러 칼럼에 함수를 적용시켜 데이터를 가공할 수 있다.
.apply(function)로 개별 원소에 function 함수를 매핑하여,
인자로 받는 function 함수에 모든 원소를 하나씩 대입하고 리턴 값을 반환할 수 있다.

미리 만들어진 함수를 apply()의 인자로 받을 수도 있지만,
lambda를 사용하여 apply() 안에서 함수를 바로 생성해주는 것도 가능하다.
이와 관련된 자세한 내용은 실습에서 다룰 예정이다.
데이터 정렬, Grouping, 외부 데이터 불러오기 실습 코드는 아래 링크에서 확인할 수 있다.
https://github.com/tldnjs1231/data-analytics/blob/main/data-analytics-03-pandas_(2).ipynb
GitHub - tldnjs1231/data-analytics
Contribute to tldnjs1231/data-analytics development by creating an account on GitHub.
github.com
'2022 데이터 사이언스 > 빅데이터 분석과 모델링' 카테고리의 다른 글
| 06. 데이터 시각화: matplotlib, seaborn (0) | 2022.06.20 |
|---|---|
| 05. Pandas(4): 타이타닉 예제 (0) | 2022.06.20 |
| 04. Pandas(3): 데이터 합치기 (0) | 2022.06.13 |
| 02. Pandas(1): 데이터 조회 및 결측값 처리 (0) | 2022.06.12 |
| 01. 데이터 사이언스란? (0) | 2022.06.12 |