데이터 사이언스는 데이터 기반의 의사결정을 위하여
통계학, 데이터 분석, 기계학습의 방법론을 통합하는 학문이다.
데이터 사이언스는 데이터로부터 의미있는 정보를 추출해내는 학문이다.
통계학과 일정 부분 유사하지만, 통계학이 정형화된 데이터를 다루는 반면,
보다 다양한 데이터를 수학과 모델링으로 분석하여 앞으로의 경향까지 예측한다는 점에서
데이터 사이언스는 통계학과 데이터 분석, 기계학습 등의 분야를 통합하는 개념이라고 볼 수 있다.

데이터 사이언스 라이프사이클(Data Science Lifecycle)
데이터 사이언스 실무는 크게 6단계로 나누어진다.
빅데이터 분석과 모델링 카테고리에서는 데이터 준비 단계부터 모델링 단계까지 알아본다.
1) 비즈니스 이해
- 업무의 관점에서 프로젝트의 요구사항에 대한 전반적인 이해
- 프로젝트 문제 파악
- 데이터 수집 방식에 대한 고민
2) 데이터 수집
- 특정 방식을 활용하여 데이터 수집 진행
- Web server(크롤링), 로그 데이터, DB, API's, 현업 담당자 제공 데이터 등
3) 데이터 준비
- Data cleansing, Transformation
- 특정 데이터 제외, 파일 확장자 변경, 데이터 합치기 등
- 가장 시간이 많이 소요되는 단계
4) 데이터 분석
- EDA (Exploratory Data Analysis) : 탐색적 데이터 분석
- 데이터 간의 상관관계, 이상치 존재 여부 등을 전반적으로 살펴보는 데이터 분석 방법론
5) 모델링
- 데이터 탐색 후 예측을 위한 모델링
- Machine learning technique, Model training, Model evaluation
6) 시스템 구현
- 현업에 적용
데이터 사이언티스트(Data Scientist)
아래 그림과 같이 데이터 사이언티스트 직군은 기술 영역과 비즈니스 영역을 포괄한다.
앞으로의 포스팅에서는 Data Analyst 직무에 해당하는 분석적 영역을 다룰 예정이다.
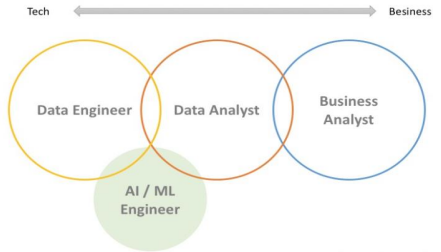
데이터 사이언티스트를 목표로 한다면 머신러닝, Python, SQL, 통계, 자연어 처리, 알고리즘과
더불어 데이터 엔지니어링에 필요한 Hadoop SPARK 등의 스킬셋이 필요하다.
또한, 이 분야는 경력이 없는 사람을 뽑지 않는다. (80%가 2~4년 경력 보유자)
따라서 데이터 사이언티스트 이전에 데이터 분석가(Data Analyst)를 거치는 것이 일반적이다.
데이터 분석가의 경우 Hadoop과 같은 엔지니어링 스킬이 빠지는 대신,
Microsoft EXCEL, Power BI 등 데이터 분석 및 시각화에 필요한 스킬셋이 요구된다.
경력이 없더라도 어느정도 대우를 받을 수 있다.
데이터 분석가 직무의 채용 공고를 살펴보면,
공통적으로 Python, R, SQL 등 데이터 처리, 분석, 모델링을 위한 언어 활용 역량을 요구한다.
R은 프로그래밍 기반의 Python에 비해 쉽게 접근이 가능해 IT보다 비즈니스 실무에서 사용된다.
Python과 R 중 하나만 잘 다룰 수 있어도 충분한데, 최근에는 Python이 많이 쓰이는 추세이다.
SQL은 데이터베이스에서 데이터를 추출할 때 필요한 언어이다.
데이터 처리 언어 외에도 머신러닝 알고리즘에 대한 이해를 요구하는 기업이 많다.
빅데이터란?
일반적으로 빅데이터의 특징은 3V로 정의된다.
Volume(규모), Velocity(속도), Variety(다양성)
규모는 데이터의 크기나 양을 의미한다.
속도는 데이터를 얼마나 빠르게 수신하고 저장할 수 있는지, 즉 데이터 관리 능력을 말한다.
빅데이터는 데이터가 방대하고 데이터 관리 능력이 탁월하다.
또, 과거에는 데이터베이스에 데이터를 저장하는 형식이 정해져 있었다면,
빅데이터의 경우 정형 데이터에 비정형 데이터가 더해져,
숫자, 문자, 음성, 이미지, 영상 등 데이터의 형태가 매우 다양하다.
오늘날 데이터의 형태에는 정형, 반정형, 비정형의 세 가지가 있다.
정형 데이터는 몇 자리 숫자인지, 어떤 문자인지 형식이 정해져 있는데 반해,
비정형 데이터는 규칙이나 형식이 정해져 있지 않아 의미 파악이 힘들다.
관계형 데이터베이스(RDB), 스프레드시트(엑셀), CSV 등이 정형 데이터에,
이미지, 영상, 음악, SNS 등이 비정형 데이터에 해당한다.
반정형 데이터는 정해진 형식과 문법이 존재하지만,
내용을 이루는 데이터의 형태가 다양하여 연산이 불가능하다.
대표적으로 웹 페이지 작성에 사용되는 HTML 언어,
웹 상에서 데이터를 주고받을 때 사용되는 XML, JSON 데이터 등이 있다.
최근에는 두 가지 특성이 추가되어 5V로 불리기도 한다.
Veracity(진실성), Value(가치)
빅데이터는 진실성 또는 정확성이 보장된다.
즉, 분석에 사용되는 데이터의 신뢰도가 높다.
또한, 빅데이터는 분석에서 그치지 않고 분석한 데이터가 의사결정에 영향을 미치고,
마케팅 등 다른 분야에서 의미 있게 사용되는 등 추가적인 가치를 창출할 수 있다.
'데이터 사이언스 > 빅데이터 분석과 모델링' 카테고리의 다른 글
| 06. 데이터 시각화: matplotlib, seaborn (0) | 2022.06.20 |
|---|---|
| 05. Pandas(4): 타이타닉 예제 (0) | 2022.06.20 |
| 04. Pandas(3): 데이터 합치기 (0) | 2022.06.13 |
| 03. Pandas(2): 정렬 및 Grouping (0) | 2022.06.13 |
| 02. Pandas(1): 데이터 조회 및 결측값 처리 (0) | 2022.06.12 |